BI系統,即商業智能系統,用來將企業或業務中現有的數據進行有效的整合,快速準確的提供報表并提供決策依據,幫助企業做出明智的業務經營決策。傳統的BI系統提供商有Oracle,IBM,Microsoft,MicroStrategy等。??
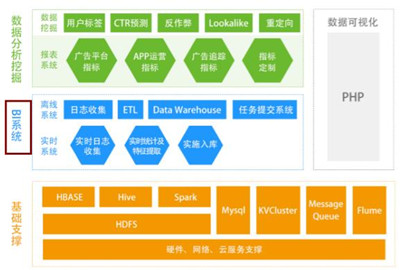
??圖1 暢思數據中心分層示意圖
??BI系統的挑戰在于數據量以及計算的效率。結合目前大數據方面的成就,這些問題已經得到的較好的解決。有能力的企業現在完全可以自己搭建自有的BI系統。
??本文以暢思平臺BI系統為例為大家介紹下BI平臺的搭建。
??BI系統主要分為數據收集、ETL以及存儲入庫、任務調度、可視化等部分。
??1 數據收集
??數據收集需要考慮如下幾個問題。
??數據源有哪些?
??數據的收集方式?
??數據的時效性、準確性、完整性?
??1.1 數據源
??數據源包括三大類:第一方數據,第二方數據,第三方數據。
??第一方數據,主要是廣告主、媒體回傳的用戶行為數據。數據一般包括用戶注冊、登錄、關卡等事件信息,可以通過對此類數據的分析,為應用運營提供統計指標,指導運營工作,如果與廣告投放數據聯合,可以進行廣告及用戶后續效果的持續追蹤以及評估;
??第二方數據,主要是廣告平臺展示、點擊、激活等數據,這類數據可用于分析廣告平臺各個項目在各類媒體上的表現使用,對流量進行評估,如果流量比較穩定,亦可用于創建用戶畫像使用;
??第三方數據主要是其他平臺合作數據,該類數據包括用戶標簽合作接入,基本流量數據。
??1.2 數據收集
??第一方數據可通過應用集成SDK采集、或者應用方直接回調等方式進行數據的收集。
??第二方數據主要是兩種方式:廣告SDK以及廣告API
??第三方數據一般采用API、第三方存儲(AWS S3, 阿里云存儲)、RSYNC等方式進行批量傳輸。
??1.3 數據的時效性、準確性、完整性
??對于第一方數據,一般按周期進行傳輸,除非BI系統提供實時服務,按周期傳輸的數據可以滿足絕大部分數據分析的需求。
??而第二方數據,由于平臺一般需要進行實時的監測,對數據的時效性以及準確性,要求相對比較高,對于時效性,基本要達到實時傳輸。因為實時傳輸經常會由于網絡的問題,導致數據傳輸的錯亂或者丟失,此時一般還需要引入離線機制進行數據的再傳輸,以保證數據的準確性以及完整性。
??一般來講,對于指標或者質量要求非常高的數據以及結果,一般采用離線傳輸和計算的方式,實時計算則提供具有指導意義的誤差再可容忍范圍之內的服務。
??1.4解決方案示例
??以暢思廣告平臺為例,如圖2所示??
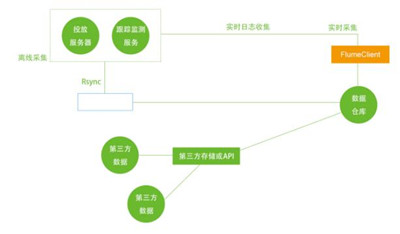
??圖2 日志收集示意圖
??第一方和第二方數據。離線分析,采用批量傳輸和獲取的方式進行數據收集;實時分析,則使用Flume進行數據的收集。第三方數據,則通過第三方可靠性存儲作為媒介如阿里云、百度云、AWS等來進行中轉,對于第三方需要實時獲取信息的,則采用API的方式進行通信。
??2 ETL
??Extract-Transform-Load的縮寫,在數據倉庫中對數據進行抽取、轉換、并加載到數據倉庫中。其主要目的是對數據進行清洗,并按照預先定義好的數據倉庫模型將數據進行規整化,以便進行后續的分析。
??現在市面是流行的ETL工具代表有: Kettle,Talend,Informatica, Datastage等。但對于平臺類的ETL,需要比較多的定制化操作,并且需要對數據進行特殊的解析或者映射,這些特殊需求導致上述的ETL工具使用起來比較麻煩。所以大家一般會自己進行ETL工具的定制開發。
??2.1 ETL需考慮的因素
??首先,確定數據倉庫的模型。要從倉庫的效率、兼容性、擴展性等多方面進行考慮。效率上考慮,把最經常使用或者分析的字段以單獨列的形式設計到模型中,并對數據進行時時間片等維度的切分;兼容性方面則一般將字段的類型設置為字符串;擴展性方面,要保留足夠的字段或者特殊的兼容性較強的字段供將來使用。
??其次,要準備好ETL使用的存儲以及計算框架。對于數據量較大的情況,建議基于Hadoop、Cassandra等文件系統進行存儲,Pregel、Yarn、Mesos等分布式計算框架進行ETL的操作。
??第三,存儲的數據格式。使用原始的數據文件,還是使用壓縮的格式;對于原始的文件,一般的分布式計算平臺會自動進行切分,而對于部分壓縮格式,則不支持文件的切分。這時候就需要在存儲與計算效率之間進行折中,如果集群存儲量有限,則使用壓縮文件,但可通過自動切分文件然后壓縮上傳的方式來提高計算效率。
??第四,ETL數據索引信息。需要提供外部的索引信息來指導分析人員進行數據的獲取以及分析。一般采用的方式是在數據庫中存儲數據倉庫各個分區的信息供分析人員查詢。
??2.2 暢思ETL
??暢思的ETL主要是基于Hive,建立數據表,數據表中的各個字段是廣告平臺或者接入方數據映射之后的字段,并預留Map結構體字段滿足將來的擴展需求。考慮到數據倉庫縱向、橫向分析的可能,對數據進行平臺、時間、類型的切分。
??在存儲以及計算框架方面,選用的hadoop生態圈的相關實現。存儲使用hdfs或者hbase,計算框架則采用Yarn。
??存儲的數據格式。目前壓縮格式較多,例如gz, scrapy, lzo,bz2等,考慮到存儲容量尤其是IO方面的需求,暢思對原始數據進行了最高級別的壓縮,并通過對壓縮數據分塊來提高計算效率。而對于數據倉庫中的數據,則采用lzo壓縮,該壓縮Mapreduce可進行自動切分。
??數據索引信息。使用mysql進行索引的存儲,并在全局記錄數據倉庫數據的開始結束時間。
??3 BI任務調度系統
??BI系統需要支持OLAP,提供復雜的分析操作,并提供直觀易懂的查詢結果,為決策提供支撐。如何從數據倉庫中快速有效的分析提取結果,是任務調度系統需要解決的問題。
??3.1 考慮因素
??首先,以什么方式讓分析人員調用。SQL的方式最為簡潔,并且因為大家對關系型數據庫比較熟悉,并且SQL在語法以及語意方面都比較完善,培訓資料較多。分析人員可以以較小的代價入門。
??第二,權限控制。對數據源、數據表等進行權限控制,防止用戶越界訪問。
??第三,結果存儲。存儲要穩健,并且能提供高并發的讀寫請求。
??第四,結果反饋。分析人員獲取結果之后,以什么方式呈現給分析人員,出錯之后如何處理。
??第五,任務調度,“調度”最為重要,需要考慮任務是否需要周期性調度,并根據任務的優先級、任務等待的時間等因素考慮任務調度的順序。
??3.2 暢思任務調度系統,如圖3所示
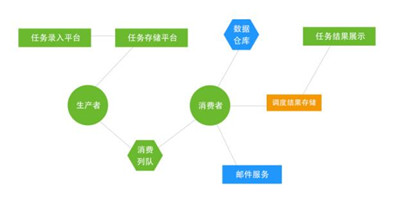
??暢思調度平臺以交互的方式提供任務提交功能。交互界面劃分權限,用戶通過界面操作將指定優先級及必須字段操作轉化為以SQL命令為主的任務序列提請到任務后臺。
??在任務調度方面,通過任務的優先級、調度周期等進行任務的分發,把不同的級別的任務分發到不同的消息隊列中。任務執行端則從消息隊列中獲取執行任務。
??任務調度的結果,則根據用戶指定的方式進行存儲或操作。如果指定為郵件發送,如果執行成功,則將結果以郵件的方式發送給配置的相關人員;如果是存儲入庫,則將結果存儲到mysql,并根據需要加載到緩存,供后續分析或者展示。
??4 可視化系統
??可視化統除了提供報表的展示、導出等功能,還要提供多維度、同比、環比等對比分析功能。BI系統產生的結果,價值的體現很大程度上體現在可視化方面。最終的可視化版本需要與產品、運營進行需求調研之后,根據業務的實際需要,提煉需要展示的維度。
下一篇:細節對成敗的關鍵影響




悅頓體育照明品牌創始人,20年來專注于各級各類體育運動場館的專業化照明!點亮精彩,照亮運動!有需要的朋友攜手合作!賬號為微信號,運動健康,你我共享!
展覽策劃 | 項目管理 | 品牌展示 深耕展覽行業20年 | 累計服務客戶2000+ | 專注品牌文化與商業價值融合(13918729898同V)







